
Timing Morton code on Python on Apple Silicon
Timing Morton code on Python on Apple Silicon
Last week I got my new Apple Silicon Macbook Pro M1. I was very excited to do some very simple tests to see how fast python could calculate the Morton Code for a 3D case. I need this for a small project I’m working on, and I found out in a previous iteration that this is taking quite some CPU time. My previous MacBook is a 13" with 2.7GHz Quad Core i7 — the top of the 13" line in 2019; the promises out there suggest that the M1 should be faster. Let’s see.
TL;DR
As many other reviews have shown, the M1 Macbooks is fast. For this simple task, both when using pure python and when using numpy, the M1 (natively) is at least 1.5 times as fast as my old macbook, with this number raising to 1.9 times as fast for the numpy 100 case.
All said, I’m very impressed.
Setup
Installation
First a quick word on installing things. The M1 machine can run both ARM code (natively) and Intel code (through Rosetta 2). I would argue that Apple actually did a wonderful job with Rosetta; almost all software runs without a hitch, and plenty fast. Installing things for ARM however are a little bit more involved (since many packages will need small changes). Already you can see daily improvements in what (homebrew) packages succeed in running natively on ARM. I’m not diving into details here on how I installed stuff (since probably that information will be outdated by next week); however for this experiment I used python 3.9.0 from homebrew (for both M1 intel and arm), and numpy 1.20rc1 which can be installed using:
pip install cython
pip install --no-binary :all: --no-use-pep517 numpy==1.20rc1
Note that this will give you a version of numpy without BLAS/LAPACK support. I also tried to run this on my pyenv installed python 3.8.5 with numpy from a wheel (including BLAS/LAPACK) on the old intel-macbook. The interesting thing is that the pure python functions were actually slower on the python 3.9.0 installations, whereas there is no difference for the numpy code.
Installing pyopencl is done (for arm) from the repo, since at the moment only master generates arm-compatible code.
pip install git+https://github.com/inducer/pyopencl
If OpenCL gave us a choice whether we wanted to execute things on the hardware or on a virtual processor, we always chose hardware.
Morton Code
The Morton Code is a number you get by combining 2 (or more) other numbers, by interlacing the bits. If you have 2 numbers, whose bits are ABCDEFGH and abcdefgh, the Morton Code is AaBbCcDdEeFfGgHh. For 3 numbers, the idea is the same: Aa_A_Bb_B_Cc_C_Dd_D_Ee_E_Ff_F_Hh_H_, if the third number is _ABCDEFGH_.
Calculating the Morton Code can obviously be done bit by bit (as done in the python_morton_naive method below). However there are some faster ways to do this; how the magic numbers work is beyond the scope of this post — I think this stackoverflow post does a good job. It should be mentioned however that this calculation is not trivial.
The code
We first setup some arrays of different sizes, each element having 3 ints (the 3 ints that we’re going to combine). (Note: full code (with hi-lighting) at the bottom of this post)
import numpy as np
def setup(count):
return np.arange(3 * count, dtype="uint32").reshape((-1, 3)) & 0x3FF
np_setup_e2 = setup(100)
np_setup_e4 = setup(10000)
np_setup_e6 = setup(1000000)
np_setup_e7 = setup(10000000)
np_setup_e8 = setup(100000000)
setup_e2 = np_setup_e2.tolist()
setup_e4 = np_setup_e4.tolist()
setup_e6 = np_setup_e6.tolist()
We use 2 methods in pure python to get to the result. First, the naive one:
def python_morton_naive(numbers):
result = []
for triplet in numbers:
r = 0
for i in range(30):
b, e = divmod(i, 3)
r |= ((triplet[e] >> b) & 0b1) << i
result.append(r)
return result
And one with magic numbers
def python_morton(numbers):
result = []
for (x, y, z) in numbers:
x = (x | (x << 16)) & 0x030000FF
x = (x | (x << 8)) & 0x0300F00F
x = (x | (x << 4)) & 0x030C30C3
x = (x | (x << 2)) & 0x09249249
y = (y | (y << 16)) & 0x030000FF
y = (y | (y << 8)) & 0x0300F00F
y = (y | (y << 4)) & 0x030C30C3
y = (y | (y << 2)) & 0x09249249
z = (z | (z << 16)) & 0x030000FF
z = (z | (z << 8)) & 0x0300F00F
z = (z | (z << 4)) & 0x030C30C3
z = (z | (z << 2)) & 0x09249249
result.append(x | (y << 1) | (z << 2))
return result
The numpy method
def np_morton(x):
x = (x | (x << 16)) & 0x030000FF
x = (x | (x << 8)) & 0x0300F00F
x = (x | (x << 4)) & 0x030C30C3
x = (x | (x << 2)) & 0x09249249
x = x << np.arange(3)
return np.bitwise_or.reduce(x, axis=1)
And then finally the opencl method
ctx = cl.create_some_context()
queue = cl.CommandQueue(ctx)
prg = cl.Program(ctx, """
__kernel void sum(
__global const uint *numbers, __global uint *res_g)
{
int gid = get_global_id(0);
uint res = 0;
for (int i = 0; i < 3; i++) {
uint x = numbers[3 * gid + i];
x = (x | (x << 16)) & 0x030000FF;
x = (x | (x << 8)) & 0x0300F00F;
x = (x | (x << 4)) & 0x030C30C3;
x = (x | (x << 2)) & 0x09249249;
res |= x << i;
}
res_g[gid] = res;
}
""").build()
def cl_morton(numbers):
mf = cl.mem_flags
cl_numbers = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=numbers)
res_np = np.empty(numbers.shape[:1], dtype="uint32")
res_g = cl.Buffer(ctx, mf.WRITE_ONLY, res_np.nbytes)
prg.sum(queue, res_np.shape, None, cl_numbers, res_g)
cl.enqueue_copy(queue, res_np, res_g)
return res_np
Note that I did not try to fully optimise the methods individually — probably a couple of percents could be shaven off each of them (and maybe more). Comparison between the methods are for “order of magintude” only.
Running the tests (only copying 1 line, see below for full listing):
print(round(timeit.timeit(lambda: python_morton(setup_e2), number=10000) / 100 / 10000 * 1000000 * 1000, 1))
....
Note that we run each test twice, and only look at the second result. This is because I did see quite large differences between the first and the second run, which I assume have to do with the memory being “laid out” when the second tests starts. So taking the result from the second test seems fairest.
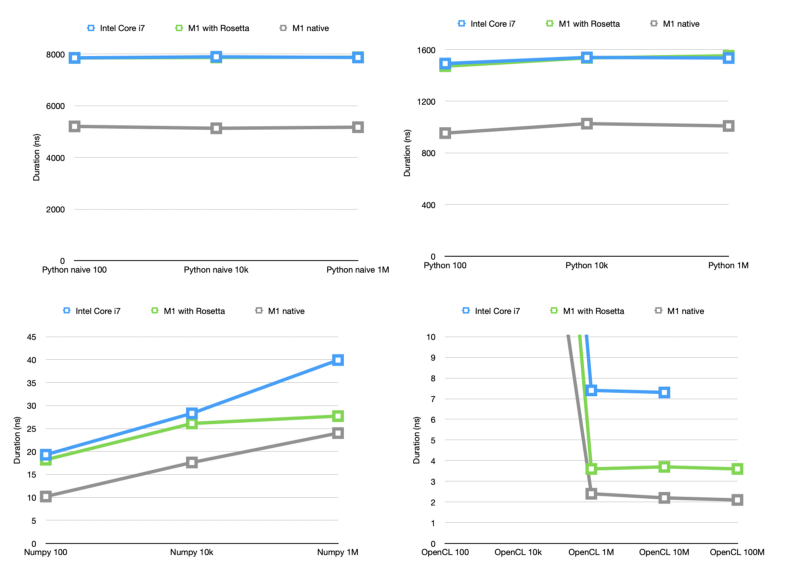
Results
When doing timings, I like to first get some idea of what kind of theoretical maximum I can expect. In this case, let’s look at the magic-number-code. To calculate a single Morton Code, this has to do 3 * (4 * (shift + or + and) + shift + or) = about 50 operations. Assuming we have a 5GHz processor, this means we should be able to do 100M of these a second, or 10 nanoseconds per code (note: this is making MAAAANY assumptions — it’s not true that processors can do 1 operation per clock tick, but it works for order of magnitude calculations). Obviously, as soon as python gets involved, things get much much slower (about a factor 100 usually works), getting us to 1000 nanoseconds per number (or 1M per second).
Now, let’s have a look at the results.
| Intel i7 | M1 w/ Rosetta | M1 native | i7 to M1 speedup | |
|---|---|---|---|---|
| Python 100 | 1491.9 | 1471.4 | 953.3 | 1.56 |
| Python 10k | 1539.3 | 1535.3 | 1026.8 | 1.5 |
| Python 1M | 1534.6 | 1552.2 | 1008.9 | 1.52 |
| Numpy 100 | 19.3 | 18.2 | 10.2 | 1.89 |
| Numpy 10k | 28.3 | 26.1 | 17.6 | 1.61 |
| Numpy 1M | 39.9 | 27.7 | 24.0 | 1.66 |
| Python naive 100 | 7853.1 | 7848.6 | 5201.2 | 1.51 |
| Python naive 10k | 7894.0 | 7867.3 | 5126.9 | 1.54 |
| Python naive 1M | 7867.3 | 7878.1 | 5169.0 | 1.52 |
| OpenCL 100 | 511.9 | 423.6 | 245.4 | 2.09 |
| OpenCL 10k | 47.5 | 44.2 | 26.6 | 1.79 |
| OpenCL 1M | 7.4 | 3.6 | 2.4 | 3.08 |
| OpenCL 10M | 7.3 | 3.7 | 2.2 | 3.32 |
| OpenCL 100M | — | 3.6 | 2.1 | — |
Firstly, we see that the results are more or less what we would expect. Our naive solution is slowest, the python magic numbers takes between 1000 and 2000 nanoseconds (we estimated around 1000), whereas the numpy solution takes between 10 and 40 nanoseconds (the fact that larger batches actually take longer in numpy is probably because allocating large swabs of memory take considerably longer — possibly we could speed things up here by reusing memory).
OpenCL has relatively high startup costs (probably for copying the memory), however afterwards is much faster. This is likely because OpenCL distributes the work over multiple GPU cores (so 2_ns_ in this case does not mean that it takes 2ns to calculate a single code, just that it can do 500M per second). The old intel macbook failed to run OpenCL on 100M codes — my guess is because they didn’t fit in the GPU memory.
Compare
As for the comparison between the systems. As has been mentioned many times before, Apple did 2 remarkable things with the release of Apple Silicon. Firstly, they produced a chip that is much faster (using less power — my old macbook regularly switched on the fan during these tests, whereas the M1 never did), and they created Rosetta 2, that allows intel programs to run seamlessly on this chip.
In these tests, the M1 with Rosetta, running an x86_64 Python with an x86_64 Numpy generally executes the code 0% to 50% faster than my old Core i7. When we compare the old i7 to the M1 running ARM native python and numpy, the speedup is between 50% and 90% (so in some cases almost twice as fast).
The OpenCL differences are even more impressive. With Rosetta, the M1 is twice as fast as the i7; ARM native, it’s even three times as fast. Now there is a lot that can be said about the OpenCL test in the way that we did it — for instance, it seems that a lot of time is still wasted in copying memory, there are settings we can tweak, and the speedup will therefore probably very much depend on the exact workload. This is probably a good subject for another post.
It would also be interesting to see if things actually get faster if we were to use Metal rather than OpenCl. This also may be a nice subject for a next post.
Full code
Expand for the full code I used. I’d be happy to hear other people’s results!
import timeit
import numpy as np
import pyopencl as cl
def setup(count):
return np.arange(3 * count, dtype="uint32").reshape((-1, 3)) & 0x3FF
np_setup_e2 = setup(100)
np_setup_e4 = setup(10000)
np_setup_e6 = setup(1000000)
np_setup_e7 = setup(10000000)
np_setup_e8 = setup(100000000)
setup_e2 = np_setup_e2.tolist()
setup_e4 = np_setup_e4.tolist()
setup_e6 = np_setup_e6.tolist()
def python_morton_naive(numbers):
result = []
for triplet in numbers:
r = 0
for i in range(30):
b, e = divmod(i, 3)
r |= ((triplet[e] >> b) & 0b1) << i
result.append(r)
return result
def python_morton(numbers):
result = []
for (x, y, z) in numbers:
x = (x | (x << 16)) & 0x030000FF
x = (x | (x << 8)) & 0x0300F00F
x = (x | (x << 4)) & 0x030C30C3
x = (x | (x << 2)) & 0x09249249
y = (y | (y << 16)) & 0x030000FF
y = (y | (y << 8)) & 0x0300F00F
y = (y | (y << 4)) & 0x030C30C3
y = (y | (y << 2)) & 0x09249249
z = (z | (z << 16)) & 0x030000FF
z = (z | (z << 8)) & 0x0300F00F
z = (z | (z << 4)) & 0x030C30C3
z = (z | (z << 2)) & 0x09249249
result.append(x | (y << 1) | (z << 2))
return result
def np_morton(x):
x = (x | (x << 16)) & 0x030000FF
x = (x | (x << 8)) & 0x0300F00F
x = (x | (x << 4)) & 0x030C30C3
x = (x | (x << 2)) & 0x09249249
x = x << np.arange(3)
return np.bitwise_or.reduce(x, axis=1)
ctx = cl.create_some_context()
queue = cl.CommandQueue(ctx)
prg = cl.Program(ctx, """
__kernel void sum(
__global const uint *numbers, __global uint *res_g)
{
int gid = get_global_id(0);
uint res = 0;
for (int i = 0; i < 3; i++) {
uint x = numbers[3 * gid + i];
x = (x | (x << 16)) & 0x030000FF;
x = (x | (x << 8)) & 0x0300F00F;
x = (x | (x << 4)) & 0x030C30C3;
x = (x | (x << 2)) & 0x09249249;
res |= x << i;
}
res_g[gid] = res;
}
""").build()
def cl_morton(numbers):
mf = cl.mem_flags
cl_numbers = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=numbers)
res_np = np.empty(numbers.shape[:1], dtype="uint32")
res_g = cl.Buffer(ctx, mf.WRITE_ONLY, res_np.nbytes)
prg.sum(queue, res_np.shape, None, cl_numbers, res_g)
cl.enqueue_copy(queue, res_np, res_g)
return res_np
# sanity check
assert np.all(np_morton(np_setup_e2) == cl_morton(np_setup_e2))
assert np.all(np_morton(np_setup_e2) == python_morton_naive(setup_e2))
assert np.all(np_morton(np_setup_e2) == python_morton(setup_e2))
print(round(timeit.timeit(lambda: python_morton(setup_e2), number=10000) / 100 / 10000 * 1000000 * 1000, 1))
print(round(timeit.timeit(lambda: python_morton(setup_e4), number=100) / 100 / 10000 * 1000000 * 1000, 1))
print(round(timeit.timeit(lambda: python_morton(setup_e6), number=1) / 1000000 * 1000000 * 1000, 1))
print(round(timeit.repeat(lambda: np_morton(np_setup_e2), number=100, repeat=2)[-1] / 1000 / 100 * 1000000 * 1000, 1))
print(round(timeit.repeat(lambda: np_morton(np_setup_e4), number=100, repeat=2)[-1] / 100 / 10000 * 1000000 * 1000, 1))
print(round(timeit.repeat(lambda: np_morton(np_setup_e6), number=100, repeat=2)[-1] / 100 / 1000000 * 1000000 * 1000, 1))
print(round(timeit.timeit(lambda: python_morton_naive(setup_e2), number=1000) / 100 / 1000 * 1000000 * 1000, 1))
print(round(timeit.timeit(lambda: python_morton_naive(setup_e4), number=10) / 100 / 1000 * 1000000 * 1000, 1))
print(round(timeit.timeit(lambda: python_morton_naive(setup_e6), number=1) / 1000000 * 1000000 * 1000, 1))
print(round(timeit.repeat(lambda: cl_morton(np_setup_e2), number=100, repeat=2)[-1] / 1000 / 100 * 1000000 * 1000, 1))
print(round(timeit.repeat(lambda: cl_morton(np_setup_e4), number=100, repeat=2)[-1] / 100 / 10000 * 1000000 * 1000, 1))
print(round(timeit.repeat(lambda: cl_morton(np_setup_e6), number=100, repeat=2)[-1] / 100 / 1000000 * 1000000 * 1000, 1))
print(round(timeit.repeat(lambda: cl_morton(np_setup_e7), number=10, repeat=2)[-1] / 10 / 10000000 * 1000000 * 1000, 1))
print(round(timeit.repeat(lambda: cl_morton(np_setup_e8), number=10, repeat=2)[-1] / 10 / 100000000 * 1000000 * 1000, 1))